相関
相関係数
相関係数(英:Correlation)とは、
確率変数$X, Y$が与えられたとき、共分散を${\operatorname {cov}[X,Y]}$、標準偏差を$\sigma_X, \sigma_Y$とした場合、下式で定義される。
式の通り、共分散をそれぞれの標準偏差で割ったものが相関係数であり、2変数間の線形関係の強さを示す指標である。
$$ {\displaystyle r ={\frac {\operatorname {cov} [X,Y]}{\sigma _{X}\sigma _{Y}}}} $$
これは期待値$E$ で表すと下式のようになる。
$$ {\displaystyle r ={\frac {E\left[\left(X-E\left[X\right]\right)\left(Y-E\left[Y\right]\right)\right]}{\sqrt {E\left[\left(X-E\left[X\right]\right)^{2}\right]E\left[\left(Y-E\left[Y\right]\right)^{2}\right]}}}} $$
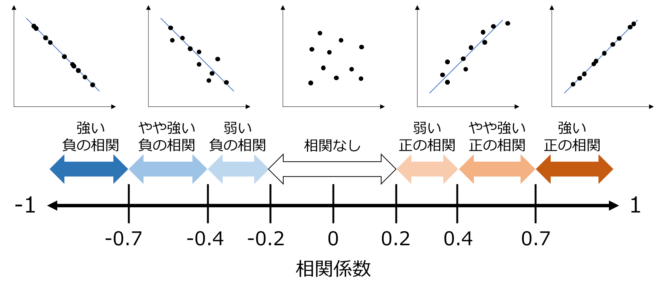
相関係数は -1.0 ~ 1.0 の値を取る。
マイナスの値をとるとき「負の相関」があると言い、0を「無相関」、プラスの値をとるとき「正の相関」があると言う。
相関係数の絶対値が大きいほど相関関係が強くなる。
決定係数
決定係数(英:Coefficient of determination)にはさまざまな定義があるものの、 相関係数$r$を二乗した$r^2$が用いられることが多い。
相関係数$r$には符号があり、マイナス、0、プラスの値を取るが(負の相関、無相関、正の相関)、
単純に相関の強弱を知りたい場合、$r$を二乗して符号を排除した決定係数$r^2$が使用される。
擬似相関
擬似相関(英:Spurious correlation)とは、 実際には2つの変数には因果関係がないにも関わらず、潜伏変数などの存在の影響で因果関係があるように見える状態。
例として、小学生の知力に関する調査をおこなうケースを考える。
この場合、「知力と身長」の間に高い相関がみられることが知られている。
これは当然ながら、年齢とともに身長が高くなり、年齢とともに知力が高くなるからであり、
この「年齢」という潜伏変数の存在に気付かなかった場合、
「身長が高いほど知力が高くなる!知力を高めるには身長を伸ばせばいいのだ!」といった誤った結論に至る可能性がある。
この例では常識的に理解が容易な変数を用いたため、簡単に疑似相関を見抜くことができるが、 専門性の高い大量の変数を分析している場合、意外と疑似相関に引っかかりやすい。 「相関関係 $\neq$ 因果関係」という点と合わせ、注意が必要である。
無相関
無相関(英:Uncorrelated)とは、 2つの確率変数 X, Y について、その共分散が0となる関係をいう。 \[ \displaystyle Cov[X,Y] = E[XY] - E[X]E[Y] = 0 \]
多変量変数の場合、分散共分散行列の非対角成分が全て0の場合、無相関となる。
なお、「無相関 \( = \) 直交」を混同しているケースが見られるが、「無相関 \( \neq \) 直交」である点に気を付けたい。
主成分分析は「多変量変数の分散共分散行列の対角化」をおこなう事に等しい。
すなわち、主成分分析は元データを無相関化する処理と考えることができる。