情報量
エントロピー
エントロピー(英:Entropy)は、事象の多様性・乱雑さを示す指標。平均情報量とも。
確率変数Xに対し、XのエントロピーH(X)は以下のように定義される。
$$ {\displaystyle H(X)=-\sum _{i}P_{i}\log P_{i}\,} $$
すなわちエントロピーとは、各事象の発生確率$P_i$に対して、重み$-\log P_{i}$をかけた値(Qと置く)を合計したものである。
これらの関係を図示すると下図のようになる。
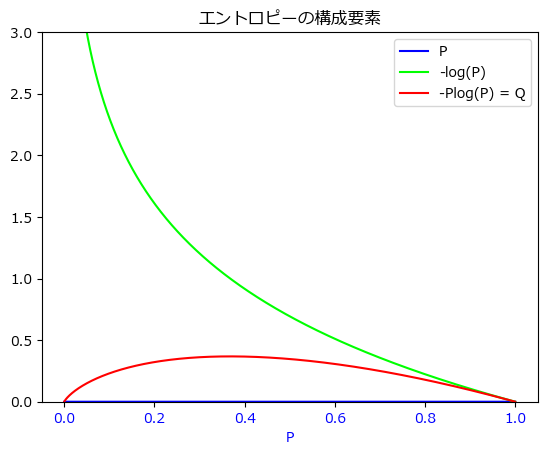
エントロピーの直感的理解
各事象の発生確率$P$は、確率変数であるからP=0.0~1.0の値をとる(上図参照)。
次に、対数関数logは定義域0.0~1.0において$-\infty$~0の値をとるため、
重み$-\log P$は、その符号を反転した$+\infty$~0の値をとる。
これはすなわち、確率1.0で発生する事象は100%発生することが分かっており、情報的な価値がないため重みを0にし、
発生確率が低くなるほど重みを大きくし、ほぼ起こりえないようなレアな事象には$\infty$に近い重みを付与する。
天気を例に挙げると、一年中晴れている砂漠地帯では「晴れ」という事象が発生する確率はほぼ1.0であり、情報的な価値がないため重みは0となる。
逆に砂漠地帯で「雨」が降ると非常に大きな重みが付与され、「雪」が降ると$\infty$に近い重みが付与される。
これが、エントロピーにおける$-\log P$の意味である。
最後に、これら2つの値をかけたものが$-P log P$である。
図からわかるように、確率1.0の「晴れ」だと値が0に、逆に確率0.0の絶対に起こりえない事象も値は0になる。
そして、それらの間の中庸な発生確率の事象になるほど大きな値になる。
つまり、「明日の天気は晴れか雨かまったく判断がつかない」というような多様性が高い状態に大きな値が与えられる。
そして、全ての事象に対する$-P log P$を合計したものがエントロピーであり、 事象の多様性・乱雑さを示す所以となっている。
情報量
エントロピーの説明で現れた重み$-\log P$のことを、
情報量(英:Self information)と呼ぶ。
選択情報量、自己エントロピーとも。
情報量$-\log P$はデータ分析系のアルゴリズムに頻出するため、
$-\log P$を見たら、上記の直感的理解を思い出すと数式の意味が理解しやすくなる。